R 기본 패키지 설치 & stm 전용 패키지 설치
install.packages("tm")
install.packages("wordcloud")
install.packages("topicmodels")
install.packages("tidytext")
install.packages("reshape2")
install.packages("ggplot2")
install.packages("dplyr")
install.packages("stringi")
install.packages("LDAvis")
install.packages("servr")
install.packages("stm")
install.packages("stopwords")
라이브러리 불러오기 & 작업경로 설정 & 사용할 데이터 불러오기
library(stm)
library(stopwords)
library(dplyr)
getwd()
setwd('C:\\Users\\user\\Desktop\\YONG\\T&DI\\STM\\BBC News Articles')
data <- read.csv('preprocess.csv', encoding='utf-8')
*전처리 csv는 이전 게시글 참고
범용어 제거 (prof. choi 참고)
stwds <- stopwords(language = "en", source = "smart")
custom = c('first', 'second', 'third', 'fourth', 'fifth', 'seconds',
'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten',
'much', 'within', 'without', 'wherein', 'will', 'wherebi',
'via', 'total', 'example', 'undergo', 'herein', 'whereby',
'may', 'can', 'along', 'also',
'therein', 'therefrom', 'therefore', 'thereafter', 'therebetween', 'therebi', 'thereof', 'therethrough',
'thereon', 'thereto', 'therewith', 'therewithin', 'therewithal', 'therewithstand', 'thereofth', 'therefor',
'say', 'said', 'saying',
'take', 'takes', 'taking', 'taken', 'took',
'made', 'make', 'makes', 'making', 'made',
'introduce', 'introduced', 'intrducing', 'introduction',
'cause', 'caused', 'causing', 'causes',
'apply', 'application', 'applicable','applies', 'applied', 'applying', 'applications',
'unit', 'units',
'apparatus', 'apparatuses',
'device', 'devices',
'enable', 'enables', 'enabled', 'enabling',
'member', 'members',
'present', 'presented', 'presents', 'presenting', 'presence',
'include', 'included', 'includes', 'including',
'invention', 'invent', 'inventer', 'inventing', 'inventor', 'inventive',
'provide', 'provided', 'providing',
'method', 'methods', 'methodology',
'use', 'used', 'uses', 'using',
'utilize', 'utilizes', 'utilized', 'utilization', 'utilizing',
'embodiment', 'embodies', 'embody', 'embodiments', 'embodied',
'relate', 'related', 'relates', 'relative', 'relation', 'relationship',
'andor')
csw <- c(stwds, custom)보편적인 범용어와 custom한 범용어를 합쳐서 csw에 저장함
기초 전처리
textProcessor와 prepDocuments 활용
mypreprocess <- textProcessor(data$document, metadata = data, customstopwords = csw,
stem = TRUE, lowercase = TRUE, removestopwords = TRUE,
removenumbers = TRUE, removepunctuation = TRUE
, wordLengths = c(3,Inf))
myout <-prepDocuments(mypreprocess$documents,
mypreprocess$vocab, mypreprocess$meta,
lower.thresh = 20)
# 수정
myout <-prepDocuments(mypreprocess$documents,
mypreprocess$vocab, mypreprocess$meta,
lower.thresh = 50)
나름의 hyperparameter라고 할 수 있는 wordLength는 단어 길이제한을 3으로 둠 (주로 영어에서 2글자 이하는 전치사, 조사 느낌이 강하기 때문으로 판단)
lower.thresh에 대해서는 적절한 값을 찾기가 애매해서 기존 예제의 20~30 선에서 선택함.
그렇게 1차 전처리한 상태로 myout$vocab 을 출력해서 커스텀 불용어에 포함할 내역이 있을지 봐야한다.
아무래도 BBC news의 article와 headline에 대한 내용이기 때문에 특정 토픽이나 기술로 내용이 굳혀지지는 않아서 단어로 인식하기 어려운 것들을 골라서 커스텀 불용어에 추가토록 한다.
* 단어로 인식하기 어려운 것들이 많아서 성능저하의 우려가 있어 lower.thresh의 값을 50으로 늘렸다.
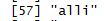
myout$vocab은

이렇게 나타난다.
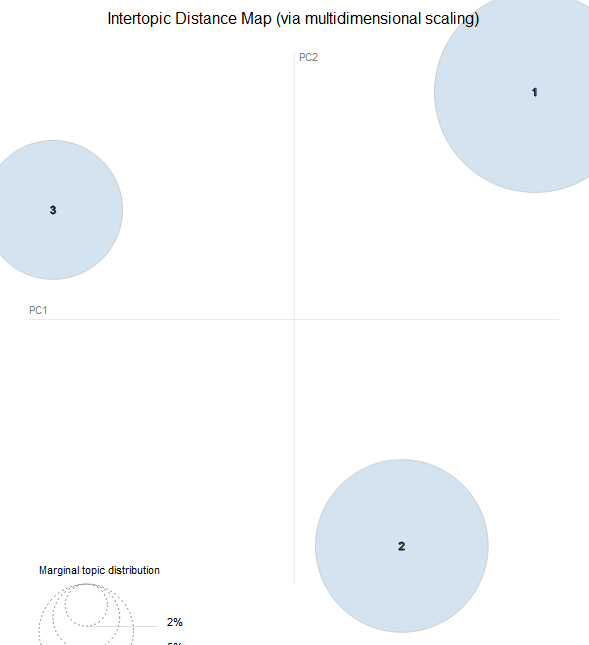
토픽의 개수를 정하기 위해 LDAvis시각화를 진행한다.
kno= # 상수
mystm <- stm(myout$documents, myout$vocab, K=kno,
prevalence = ~ date,
data=myout$meta,
seed = 16, init.type = "Spectral")
toLDAvis(mystm, myout$documents)
kno=3,5,7

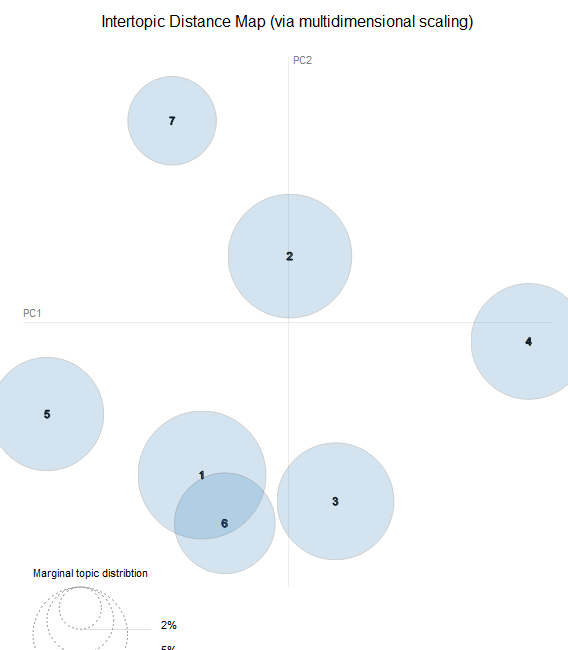
kno=9, 10, 11



그 이상의 kno값을 지정해도 되겠으나 비교적 분포가 잘 되어 있으며 겹치는 영역이 적은 kno=10인 경우에서 추가 분석 및 토픽 해석을 진행하겠다.
'T&DI LAB > 토픽모델링' 카테고리의 다른 글
| USPTO Patent View API에서 특허 데이터 추출하기 (1) | 2024.01.05 |
|---|---|
| STM 실습 (4) 토픽모델링의 해석 / 의의와 한계 (1) | 2023.11.15 |
| STM 실습 (2) 데이터 가공 (0) | 2023.11.14 |
| STM 실습 (1) 데이터 탐색 및 목표 설정 (1) | 2023.11.14 |
| LDA modeling 실습 : 타다 금지법 기사 댓글 분석 (2) | 2023.11.05 |