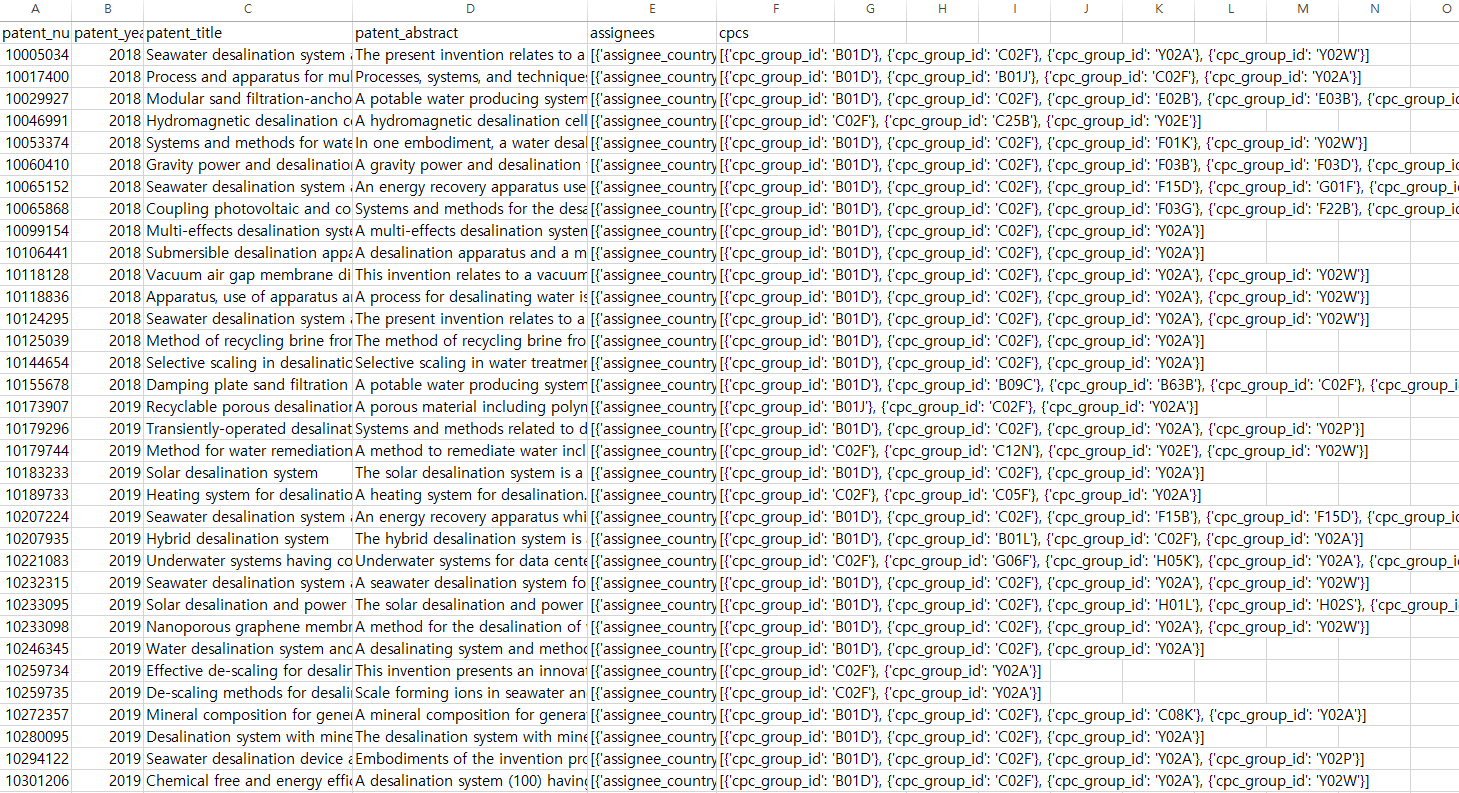
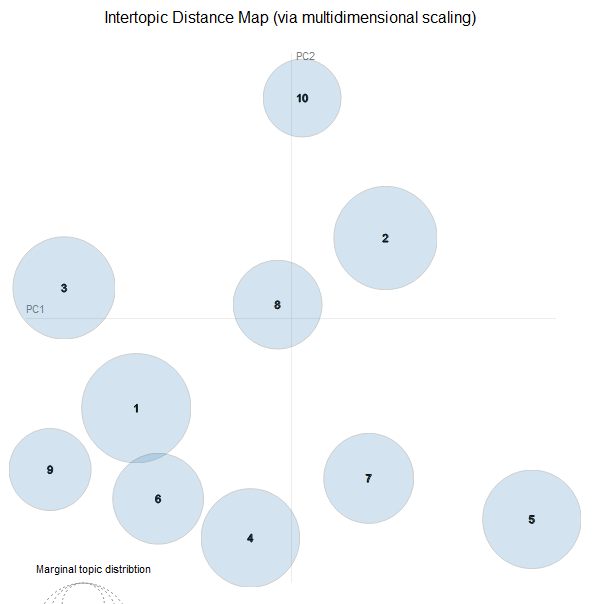
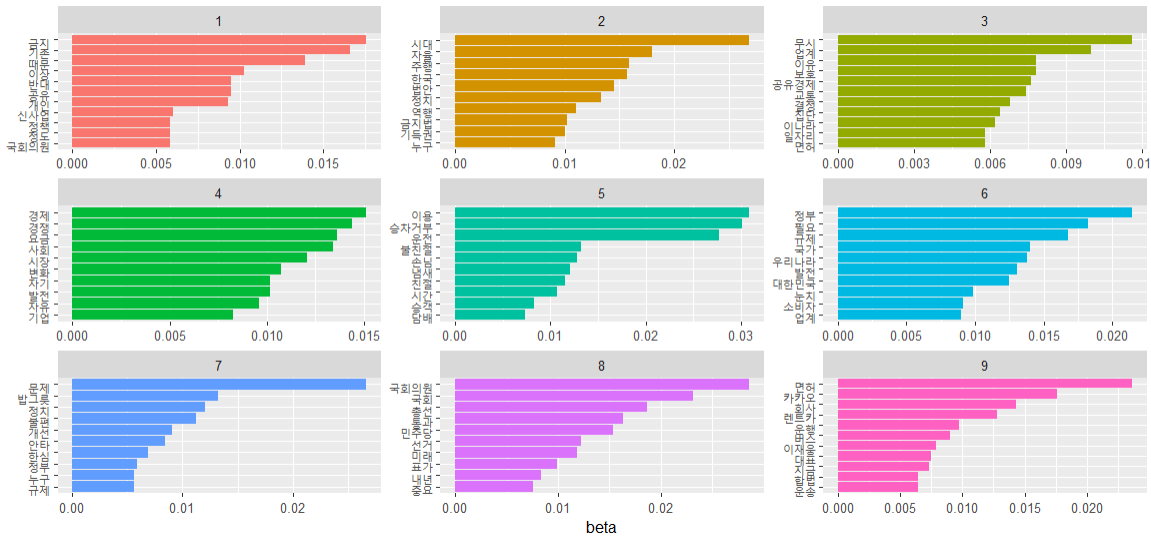
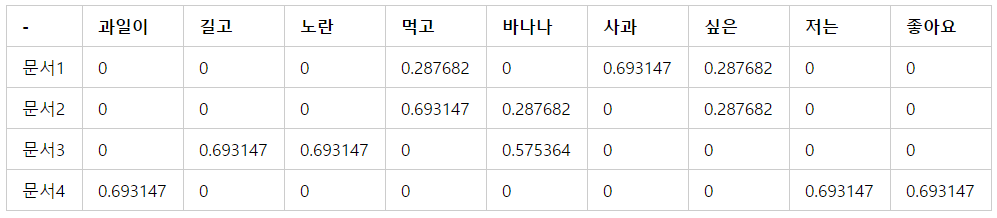
전처리가 가장 힘든 과정이다 특히 다운받은 API 데이터는 json 데이터 타입으로 구성되어 있다. 흔히 알고 있는 csv 파일과 다르게 json 파일은 데이터를 키-값의 쌍의 집합으로 표현하는 것이다. (딕셔너리 형태라고 이해) 예를 들면 name,age,city John,25,New York Alice,30,San Francisco Bob,22,Los Angeles 와 같이 구성된 경우 [ {"name": "John", "age": 25, "city": "New York"}, {"name": "Alice", "age": 30, "city": "San Francisco"}, {"name": "Bob", "age": 22, "city": "Los Angeles"} ] 처럼 표현되어 있는 형태를 말한다. ..