Redirecting
linkinghub.elsevier.com
Instroduction
와해성 혁신(disruptive innovation)은 현존하는 기술 패러다임을 쓸모없게 만들었다.
와해성 혁신을 통한 새로운 기술은 기업의 경쟁우위에 있어 매우 중요한 촉진제가 되었다.
이러한 까닭에 많은 회사들이 기술 혁신에 많은 예산을 투입하고 있다.
새로운 기술의 발견이 곧 회사 입장에서 상당한 이익을 안겨준다는 것이다.
현재의 기술 기회와 관련된 문서들은 분석적 방법, 성능, 세부 사양 등에서 한계를 가진다.
l 전문가의 의견에 의존적임(검증이 매우 어려움)
l 기술 공백에 대한 시각화에 있어 과연 공백 영역에 대한 의미가 명확하지 않음
(기술의 세부적인 부분에 대해 결과론적으로 약점을 가지고 있음)
l 기존의 방법들은 매우 러프(rough)한 공백 기술 영역 탐색에는 적합하고 양적으로는 특히 시스템적이지 않으며 R&D 계획에 실질적 실행여부와는 꽤 약하게 연결성을 띄어 부적절함.
è 이러한 까닭에 본 연구는 기술 기회(technology opportunity)탐색에 있어 시스템적인 접근 방법을 모색하고자 함 (특허정보를 시각적으로 지도화하고 텍스트 마이닝을 통해 키워드를 추출할 것이며 빈 영역의 의미를 명확히 할 수 있는 방법을 고안해 보겠다)
여기에 GTM(Generative Topology Mapping)이 매우 유용하게 사용될 수 있음(공백영역 탐색에 매우 적합하고 나아가 링크되어 특허 지도와 네트워크를 탐색하고 예측할 수 있기 때문)
Technological background
덾파이 기법(전문가의 경험적 지식을 통한 문제해결 기법, Delphi approach)은 정성적인 분석에 용이하고 TOA(Technology Oppoortunity Analaysis)는 정량적인 분석에 용이하다. TOA의 관점에서 기술정보는 4가지 카테고리로 분류할 수 있다. (특허를 포함한 상태로, 과학기술적 학술지, 연구자, 상품(제품), 프로세스).
특허분석은 정량적으로서 텍스트마이닝과 계량서지학(biblometric)적 연구에 있어 핵심 분석도구로 여겨진다. 대부분의 특허분석은 차트, 그래프, 네트워크와 같은 다양한 시각적 도구를 제공한다. 특히 텍스트 마이닝은 기술 혁신 트렌드 분석과 네트워크 분석, 인용피인용 분석과 함께 결합하여 활용된다.
한편, 과학적 기술적 부분에서의 연구는 서로 상호작용하면서 도움을 주는 관계에 있고 특허분석에서도 이러함이 들어난다.
또한 특허분석에 있어 시각적인 분석은 함의를 도출하는 과정에서 핵심이며 선행연구로서 진행된 특허 분석 시각화 연구는 아래와 같다
l Chang et al. (2009) – 계량서지학 특허분석을 통한 기술 트렌드 프레임워크 제시함
l Tang et al.(2012) – ICT(Inventor-Company-Topic)모델, 다자원적(heterogeneous) 특허네트워크 분석을 통한 모델 제안함
특허분석 시각화에 앞서 기본적으로 특허는 비구조적 텍스트이므로 전처리 단계로서 자연어를 처리하는 추가적인 공정이 필요함 (NLP는 SAO(subject-action-object)와 keyword-based 로 분류할 수 있다). SAO가 문장의 구조화에 집중한다면 keyword-based는 keyword를 추출하는 것에 집중한다. 그리고 SAO는 TOA에 있어 매우 중점적으로 활용되고 있다. SAO와 관련한 선행연구로서 진행된 분석 시각화 연구는 아래와 같다.
l Yoon et al.(2013) – 동적으로 구조화된 특허 지도를 구성함
l Choi et al.(2012) – 기술 나무를 구조화함
l Lee et al.(2015) – 텍스트 마이닝(특히, 단어 사용도와 outlier 요소로서)으로 novelty-focused patent map을 만듬
최근에는 Word2Vec과 LDA와 같은 텍스트마이닝 기술이 등장했다.
마지막으로 Link Prediction이라는 연구분야가 존재하는데 많은 선행연구도 존재했다. 그러나 생물학적 혹은 사회학적 네트워크와 관련된 데이터는 불완전, 부정확한 경우가 있고 비논리적인 연결관계를 포함할 수 있다. 또한 지도학습적 관점에서 테스트 데이터 셋에서 기존의 머신러닝 방법론(로지스틱회귀, SVM(Support Vector Machine), Bayes, 신경망 네트워크)으로 문제를 해결할 수는 있으며 Hansen et al.(2006)에서 SVM(and bagging)이 사회학적 네트워크 분석에 있어서는 성능상으로 우수하다고 발견한 바 있다. 한편 유사도의 관점에서 두 노드 간의 거리가 짧을수록 미래의 시점에 연결될 가능성에 대한 확률을 높이는 방법론도 더러 소개되었던 바 있다. Katz와 vertex similarity(Jaccard coefficient, Cosine similarity), 베이지안 확률 등
è Link Prediction을 통한 기술 기회 분석은 incremental , radical technology에 적용하기 어려운 문제를 가진다. Incremental and radical technology는 서론에서 얘기했듯 와해성 혁신으로서 새로운 시장을 개척하기 때문에 미래 시장 예측에 부적절한 단점을 가진다.
The Proposed approach
다시 얘기하지만 본 연구에서는 기존의 연구에서 더해 특허정보 시각화를 시도하는데 특허 지도와 특허 네트워크를 결합하여 사용함으로써 기술적 공백 영역에 대해 분석하고 기술간 유사도를 파악할 것이다. 이때 기술의 유사도란 각 특허 문서에 있는 키워드와 특허 문서의 인용 정보(새로운 특허는 반드시 이전의 특허를 인용한다는 가정)에서 출발한다. 또한 본 연구에서 기술 기회란 기존 특허 지도에 존재하는 파생 기술의 영역이 아닌 혁신에 의한 새로운 기술로서 그 의미를 해석하는 게 적합하다.
-Framework
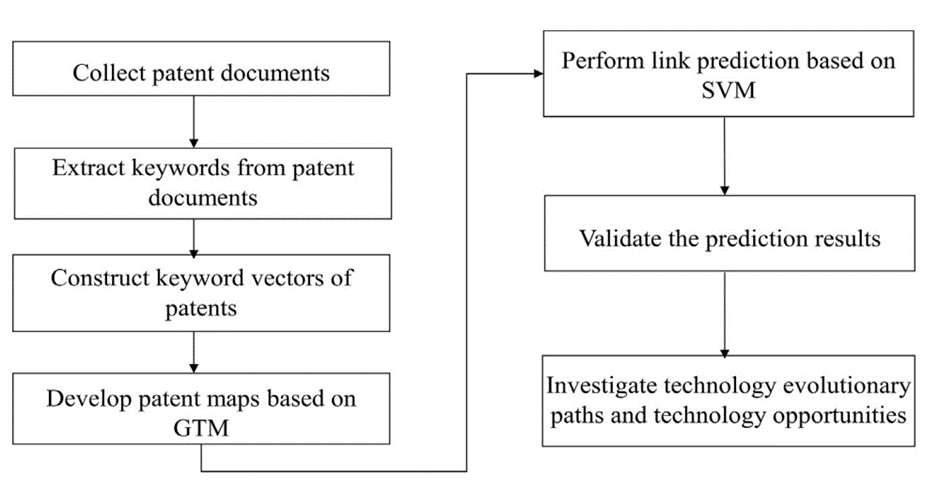
1) 특허 데이터베이스에서 관심 데이터 수집
2) 텍스트 마이닝 기법을 통한 키워드 추출
3) 키워드 벡터와 발생 빈도를 구함
4) GTM과 키워드벡터를 활용한 특허 지도 개발
5) 기존 특허와 빈 셀의 Link prediction을 진행하고 예측 오류 계산 및 검증
데이터를 수집할 때는 UPC와 IPC모두에 등록된 특허 클래스를 결정하고 교집합에 속한 특허가 대표적인 특허 클래스라고 판단할 수 있음(Criscuolo, 2006)
키워드 벡터를 만들 때 단어의 존재만을 고려한 이진 값 분류와 이를 가중치로서 생각할 수 있도록 구성한다. 또한 불용언을 제거함으로서 문서의 크기를 줄일 수 있고 어간(stemming)을 분석함으로써 접미사(suffix)를 제거할 수 있다. 그리고 TF-IDF로서 많은 문서에 나타나는 비교적 흔한 단어를 인식할 수 있다.
이제 GTM을 사용해서 특허지도를 그려야 한다. GTM은 2차원 평면에 특허의 위치를 시각화함으로서 공백영역과 밀집 영역을 찾을 수 있는 특징이 있다. GTM의 역함수를 통해 빈 셀의 추정 키워드를 지도에서 찾을 수 있으며 본 연구에서는 X가 미개발 기술의 영역을 의미하도록 시각화 하였고, W가 초기 가중치 행렬을 의미하며, pi(x)는 잠재 변수에 대한 기저 함수의 활성화 함수이다. Y를 통해 mapping transformation을 진행한다.
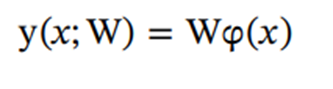
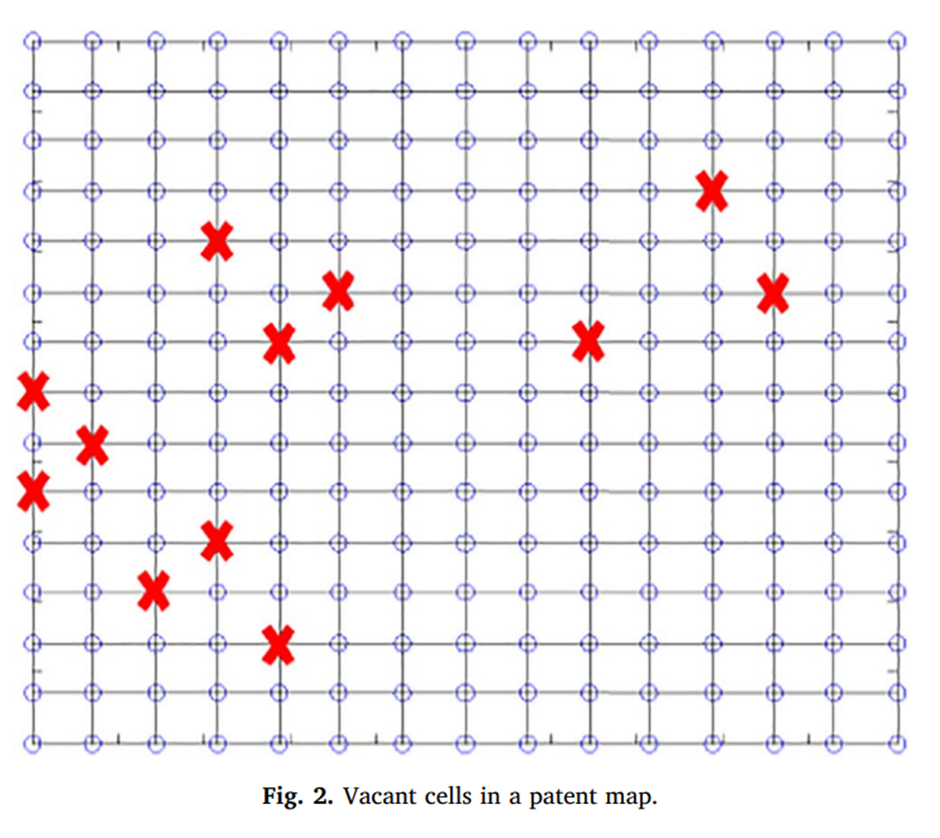
물론 모든 공백 셀이 기술 기회로서 인식되지는 않는다(앞서 언급한 link prediction의 단점)
Application of the approach to three technologies
3가지 기술 영역에 대해서 적용해보고자 한다.
증가하고 있는 기술 영역인 3D 프린터, 유지되고 있는 영역인 물 정화, 감소하고 있는 영역인 핵 융합과 관련된 기술 영역에 대해서 다뤄보고 있다. 증가, 유지, 감소에 대해서는 특허의 개수로 판단을 한다. 한편 2006~2014년의 기간을 3개의 period로 나누어서 접근하였는데 일반적으로 기술의 주기를 3년으로 정하는 것이 적합하다고 판단하였고 그 근거는 선행 연구자료에 기반했다.
총 3D프린터 251개, water purification 745개, nuclear fusion 690개가 존재했고 각각에서 keyword를 추출하여서 198, 245, 182개의 키워드 벡터를 통해 특허개수X키워드벡터개수 로 구성된 행렬을 생성한다.
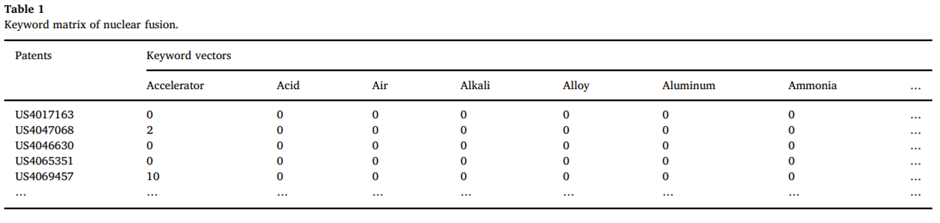
2차원 행렬을 통해 GTM을 그릴 수 있고 GTM은 파이썬, R등에서 제공하고 있는 것으로 파악되었다. (github에 존재했음)
GTM을 만들 때 파라미터 값을 사용자가 지정해야 하는데 그 중에서도 지도의 사이즈를 정하는 것이 매우 중요하고 본 연구에서는 10*10, 12*12, 15*15로 3가지 경우에 대해서 진행했으며 200-1000개의 특허 양에 대해서는 연구자가 12*12의 사이즈가 적당하다고 판단했다. 각 기술영역에 대해서 link prediction을 할 때 사용하는 지표로는 recall, precision, lift를 사용하고 lift(향상도)의 경우 1보다 크다면 예측이 랜덤에 의한 것 보다 유의할 정도로 크다는 것을 의미하고 link prediction 의 validation을 위해서 카이제곱 검정을 진행한다. Link prediction에 대해서 similarity – based 와 SVM 두가지의 성능을 비교했으나 모든 부분에서 의미유사도 기반의 link가 더 우수했다. 본 연구에서는 따라서 의미 유사도 기반으로서 각 기술 영역의 link prediction을 실시하고자 한다.
Discussions
본 연구를 통해 특허 문서를 특허 인용 정보만큼으로 활용할 수 있게 되었다. 한 그림안에 특허 네트워크와 특허 지도를 함께 그릴 수 있게 되었다.
지도에 있어서 다양한 시각화 도구와 방법이 존재하나 본 연구에서는 GTM(후술) 으로 연구를 진행했으며 GTM은 patents map을 그리는 것에 적합하다. GTM을 통해서 추정되는 공백 기술의 keyword vector를 찾을 수 있다는 점이 시사하는 바가 크다. Keyword vector를 찾을 수 있다는 점은 의사결정자로 하여금 기술 기회(technology opportunity)의 세부 사항까지 자세하게 알려줌으로써 기술 계획의 과정을 지원할 수 있다는 장점이 있다.
한편 네트워크에 있어서 link prediction에서 기존에 neiborhood-based approach와 path-based approach 가 주로 사용되었으나 이들은 기존에 존재하는 노드에 대해 놓친 링크를 예측하기 때문에 존재하지 않는 링크의 예측에는 적합하지 않았다. 앞서서도 언급했듯 따라서 semantic similarity-based-approach와 SVM을 사용했고 그중 전자의 성능이 우수했음을 서술한 바 있다. SVM이 성능상으로 부족했던 이유는 본 연구에서 사용한 데이터의 양이 기계학습(ML)에서 강력한 결과를 도출하기에 양적으로 적었다(1000개 이하). 두 번째로는 두 방법에서 사용하는 정보의 종류와 양에 차이가 있는데 semantic-similarity based 는 유사도를 측정할 때 keyword vector만을 사용했었다. 그러나 SVM은 키워드벡터와 인용정보 사이의 유사도를 측정하다보니 링크가 복잡해지고 부정확하게 되어 학습에 있어 부적절한 요소로 작용하게 되었다. 이러한 까닭에 semantic-similarity based approach가 본 연구에서 사용되었다.
마지막으로 기술 예측에 있어 먼 미래에도 언제든지 나타날 수 있는데 본 연구에서는 period를 3개로 나누었고 초기 period에 대해서 나머지 두 period의 예측을 시도했으므로 해당 미래 시점에는 아주 적게 나타나더라도 얼마든지 시장과 상품에 있어 큰 영향력을 가진 기술이 미래에 나타날 수 있어서 manager는 long-term의 관점에서 확률적으로 바라볼 필요가 있다. 즉 분석가는 기회로서 바라봐야 하지 예측성능과 에러로서 바라보는 것은 본 연구의 방향성과 맞지는 않다. 따라서 본 연구에서 제시한 정보는 support정도로만 이해하고 이와 함께 시장, 상품, 경쟁자 등과 같은 다양한 정보를 함께 탐색하여 판단할 필요가 있다.
Conclusions
본 연구가 가지는 한계를 위주로 이야기하면, link prediction에 있어 다양한 방법을 시도하지 못한 점, 예시로 분석한 3D프린팅 기술, 물 정화기술, 핵융합기술이 각 카테고리에서 일반화된 insight를 제공하지 못했다는 점, 공백 셀에 대한 결과를 해석할 때 분석가의 주관적인 의견이 들어갔다는 점 등을 꼽을 수 있고 추후 연구에서 보완되기를 바란다.
+@ Generative Topology Mapping (GTM) , GTM이란 무엇인가 ?
본 연구에서 GTM을 사용하였다고만 하였지 어떤 내용인지 자세하게 알기 어려워
https://www.microsoft.com/en-us/research/wp-content/uploads/1998/01/bishop-gtm-ncomp-98.pdf
을 참고해서 추가로 정리했다.
-GTM은 SOA(Self-Organizing Map)의 대안으로서 제안되었다.
GTM은 EM(Expectation-maximization)을 목적식으로서 가우시안 혼합 모델을 제약식으로 하는 알고리즘이다.
비선형적으로 차원축소를 통해 mapping을 수행한다는 점이 PCA와 같은 다른 알고리즘과의 차이라고 볼 수 있으며 확률적으로 데이터 포인트를 저차원 공간에 매핑하고 있다. 차원을 줄이게 되어 시각적으로 해석하는데 매우 용이하다.
저차원 공간에 기록된 각 데이터 포인트로부터 이후 link prediction을 진행하고 있다.
*참고 gtm python code*
https://github.com/innovationb1ue/GTMX
GitHub - innovationb1ue/GTMX: A Python package for Generative Topographic Mapping (GTM)
A Python package for Generative Topographic Mapping (GTM) - GitHub - innovationb1ue/GTMX: A Python package for Generative Topographic Mapping (GTM)
github.com