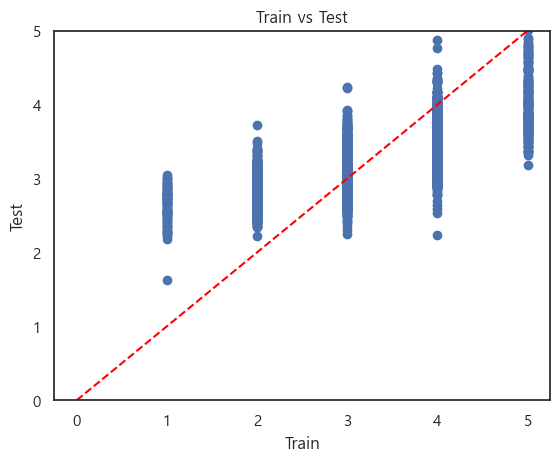
수업에서 배운 오로지 수업에 의한 기본적으로 성능을 고려하지는 않음 우선, 다시 스케일링을 했다. 이유는 통일성을 위해서와 여러 전처리를 겪다보니 상당히 더러워진 데이터를 처음부터 정제하기 위해서. 아무튼 다시 전처리를 진행했고 그 내용은 (2) 와 별반 다르지 않다. 이를 바탕으로 Regression이나 Classification 모두를 사용해보았다. 물론 Regression이 연속형 데이터 셋에서 사용해야겠지만 처음에 의도했던 가중치를 구하고 점수화하기 위해서는 Regression도 꽤 괜찮은 시도이지 않나 생각한다. (반박시 니말 맞음) import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linea..