부스트코스의 무료강좌인 파이썬으로 시작하는 데이터 사이언스 (박조은) 강좌에 대한 학습을 바탕으로 요약한 내용입니다.
chapter 3에 해당하는 내용인 서울시 의료기관 분포 확인하기입니다.
처음 데이터분석을 실습해보는 과정이라 정말 기본적인 수준으로만 진행을 해봤습니다.
내용을 따라가면서 학습했을때 궁금했던 과정은 데이터 전처리 과정이었습니다.
과연 데이터를 전처리하는 방법이 정말 단순히 가정에서 출발해 일일이 솎아내는 방법뿐일까에 대한 의문이 생겼습니다.
서울시 종합병원을 분류할때 상호명을 기준으로 전처리를 진행하는데 특정 키워드가 들어간 상호명을 빼는 과정으로 전처리를 했기 때문이죠, 그렇다보니 애매한 키워드는 적절히 전처리가 불가능하였습니다.
이를테면 "의원" 단어가 들어갔음에도 종합병원일 수도 있고 "재단"이라는 단어는 종합병원이 아닐수도 있으니까요,
만약 병원 상호명이 "종합의원"이었다면 어떻게 해야했을까요?
folium 이라는 라이브러리를 다운로드하여 Map 상에 표시하는 것은 꽤 흥미롭게 다가온 skill이었지만 현재로서는 데이터 전처리에 대한 고민이 조금 더 생긴 프로젝트 실습이었던 것 같습니다
해당 강의에서 진행한 방법으로 데이터 분석을 해보았더니

우리나라에 분포된 병원의 위치입니다. 음 아무래도 지방의료의 문제점을 확실히 볼 수 있는 데이터네요, 단순히 부족하다가 아닌 시각화를 통해 보니 확실히 군데군데 비어있고 일부지역은 아플때 즉시 치료를 못받을 수도 있겠다는 안타까운 생각도 들었습니다.
외데도 서울시 종합병원의 데이터를 한번 볼까요?
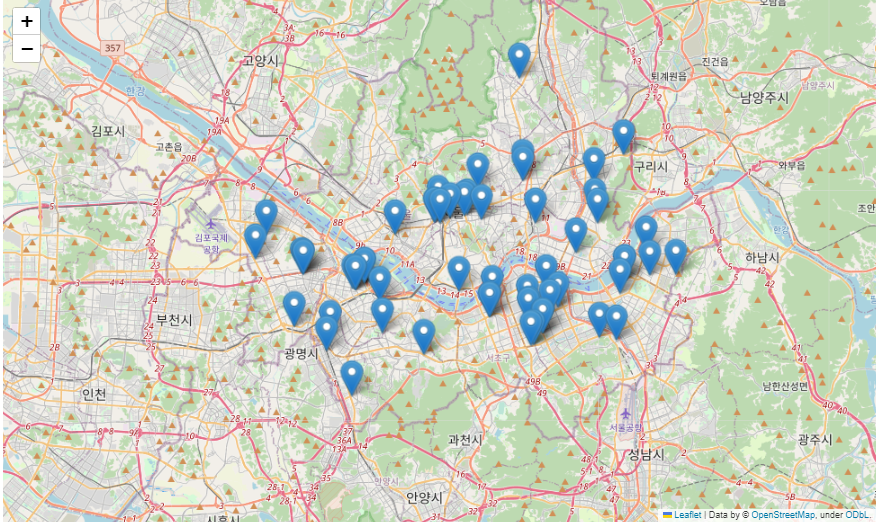
다소 불편한 전처리 과정이 있었지만 어느정도의 오차와 신뢰성을 고려한다면, 분명 서울역시 외곽으로 향할 수록 종합병원의 숫자는 부족해 지역간 격차가 존재한다는 것을 보여주는 그림인 것 같습니다.
마지막으로 주피터 노트북을 사용하시는 분이라면 !

코드를 조금 더 깔끔하게 정리할 수 있는 nbextension 기능을 소개해봅니다. 인터넷에 다양한 설치방법이 있으니 편한 방법으로 설치하시면 매우 유용한 도구로 사용할 것 같습니다.
'IE & SWCON > Data Science' 카테고리의 다른 글
| 새로운 비만 평가 지표를 만들기 위해서 (2) (1) | 2023.11.14 |
|---|---|
| 새로운 비만 평가 지표를 만들기 위해서 (1) (0) | 2023.11.10 |
| [금융공공데이터취합] 재정패널조사 (0) | 2023.09.16 |
| [캐글] 랜덤포레스트 회귀기법으로 자전거 사용량 예측하기 (0) | 2023.05.01 |
| [부스트코스] 건강정보데이터 분석하기 (0) | 2023.03.22 |