데이터는 캐글에서 제공하는 워싱턴시의 2011~2012년간 자전거 대여량에 관한 csv data입니다. 우선 랜덤포레스트로 예측을 시작하기 전에 제공되는 데이터의 구조와 개요에 대해 알아봐야 할 것 같아 기본적인 시각화를 진행해보겠습니다. 데이터 분석 프로젝트에서 이런과 정을 EDA, 탐색적 데이터 분석이라고 합니다. 하는 이유라고 한다면 맛있는 요리를 만들기 위해 서 맛있는 식재료가 우선이 되어야 하고 식재료가 간단하면 조리방법이 간단해도 맛있는 요리가 나온다는 상황을 가정하시면 될 것 같습니다.

데이터 분석이라고 하는 프로젝트의 포괄적인 개요는 다음과 같이 진행이 될 것 같습니다.
1. 데이터 정보 확인


데이터를 설명하고 있는 내용입니다.
위의 데이터 중 살짝 이상한 부분이 있어 후에 수정을 해야 할 것 같습니다. season을 보시면 1 에 해당하는 값이 봄이라고 나와있는데 보통 1월을 봄이라고 인식하지는 않듯, season 값을 계절에 맞게 고쳐주는 가공작업을 해야할 것 같습니다. 그리고 windspeed쪽을 보면 0이 꽤 존재하죠? 바람이 안 분다는 것은 일상생활에서 받아들이기 어려우므로 누락된 값일 수 있겠다는 생각을 해보면서 다음 단계로 넘어가겠습니다.
이후 기본적인 시각화에서 사용할 라이브러리를 불러오고 사용할 데이터를 읽어보겠습니다.
2. 데이터 시각화
흔히 많이 사용하는 plot 라이브러리를 사용해서 시각화를 진행해보았습니다. 코드 자체도 간단한 편이고 코드 보다는 그래프를 공유하는 것이 나을 것 같습니다.


3. 결측치 이상치 제거
다음은 히트맵입니다. 랜덤포레스트를 하는 이유가 test.csv에 있는 데이터의 변수들을 바탕으로 count를 예측하는 것이고 예측할 때는 관련 변수가 꽤 필요합니다. count에 영향을 미치는 변수들 이 얼마나 있는지 상관계수를 본다면 학습할 feature를 정할 수 있습니다. humidity를 살짝 보고 싶은데, -0.32라는 값은 비록 – 상관관계이긴 하지만 절댓값의 크기는 유의 미하기 때문에 변수변환을 살짝해서 -0.32 를 +0.32로 바꿔보겠습니다. 습도의 값을 전부 음수로 바꾸어 보겠습니다. 아 참고로 registered는 너무 1에 가깝기 때문에 과적합이 일어날 수 있어 학 습 feature에서 제외하도록 권장하니까 빼보겠습니다.
다음으로, 랜덤포레스트를 사용하려면 일단 결측치가 없어야 합니다. 처음에 windspeed에 대해 말씀 드렸던 것을 기억하시나요? 0의 값이 너무 많아 보이고 기록이 누락된 것으로 보여서 수정이 필요할 것 같다고 했습니다. 전체의 만 여개의 데이터중에 0으로 기록된 값이 1300여개라는 것은 무시할 수는 없는 데이터의 양입니다.
이렇게 0으로 기록된 값을 채워줄 때 사용하는 방법으로는 선형보간법, 평균으로 대체하기, 머신 러닝으로 학습시키기 등 다양한 방법이 있습니다. 저는 머신러닝으로 학습시키기로 0의 값을 대 체해보겠습니다. 사용할 머신러닝 기법 역시 랜덤포레스트고 여기서는 분류기법을 사용할 것인데 큰 맥락에서 랜덤포레스트라는 내용은 비슷하니까 잠시후에 자세히 설명 드리겠습니다. 아무튼 다음과 같이 0을 대체하고 나면 다음과 같은 결과를 그래프로 얻을 수 있습니다.
아까 0 이 많았는데 지금은 없어진 것으로 보여집니다. 마찬가지로 train 과 test 모두에 적용을 해보겠습니다



4. 상관분석과 feature 선택
랜덤포레스트를 사용하기 위해서는 필요한 라이브러리들이 꽤 있는데요 우선 import하겠습니다.
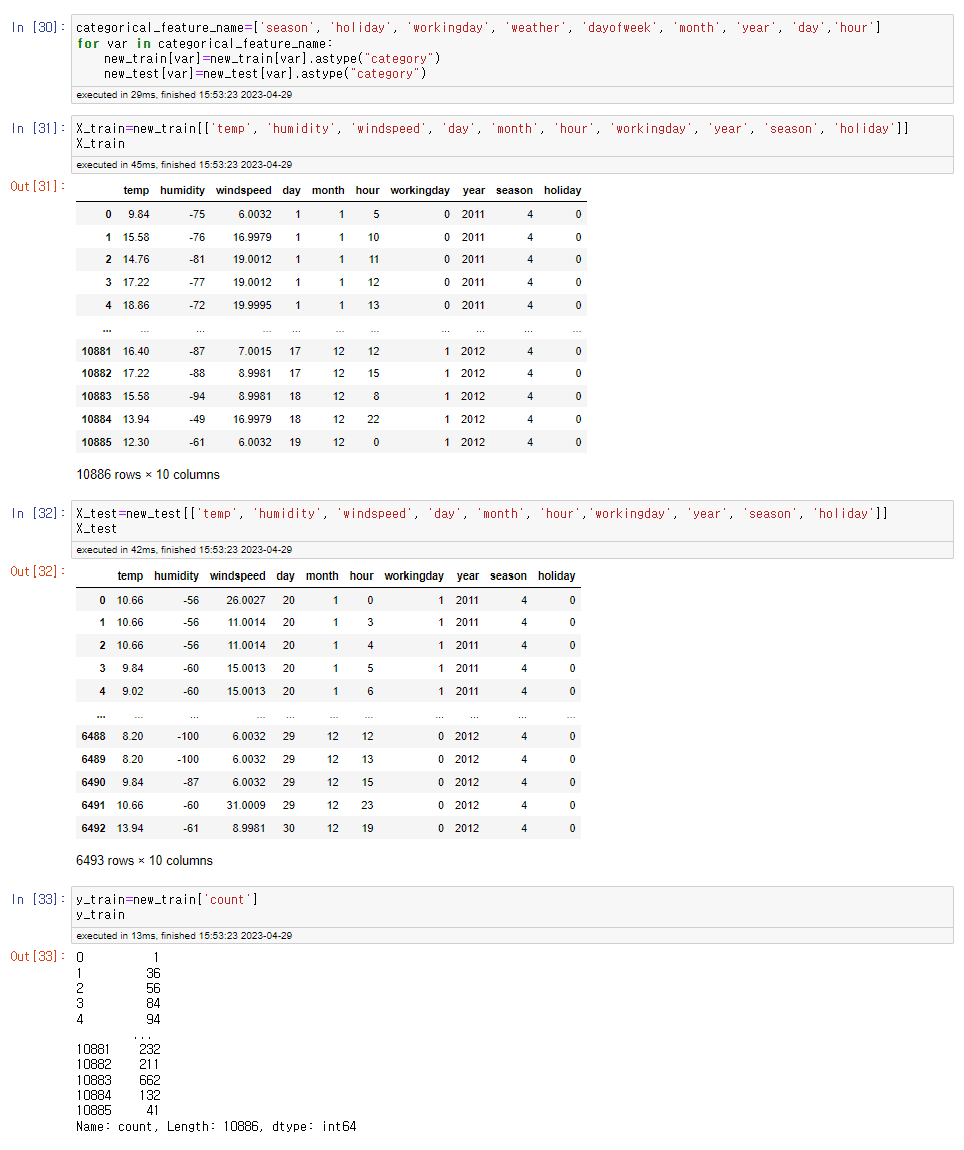
학습에 사용할 피쳐는 아까 히트맵에서 상관계수가 높은 것들을 위주로 골랐습니다. 일부 데이터 는 범주형 데이터라서 category로 타입변경을 해주었습니다. 예시를 들자면 원본 데이터에서 봄 을 1, 여름을 2, .. 계절을 각각 1,2,3,4로 표현을 했지만 이는 나누기 위한 것일 뿐 실제로 봄의 값 을 두배로 하면 여름이 되는 듯 산술적인 관계가 아니므로 이런 범주형 데이터들을 카테고리로 묶어주면 됩니다. 이에 반대되는 개념은 수치형 데이터인데 이는 직접적으로 값이 구하고자하는 count에 영향을 주는 경우를 의미합니다.
Train에 학습에 사용할 피쳐만 따로 골라 새로운 데이터프레임을 만들어보겠습니다. 마찬가지로 Test에도 동일하게 진행하며 y_train에는 count값만 두고 이를 통해 y_test를 예측하고자 변수구분 을 실시하겠습니다
5. 모델학습 및 평가
우리가 예측을 했을 때 예측된 정도를 평가할 지표가 필요합니 다. 여기서 사용할 평가지표는 RMSLE이고 오차의 제곱값에 대한 평균을 제곱근을 사용하는 지표 입니다. 따라서 0에 가까울수록 예측값이 비교적 정확하다고 볼 수 있습니다. 파이썬에서 따로 라 이브러리로 제공하지 않아 코드로 함수를 만들어보겠습니다.

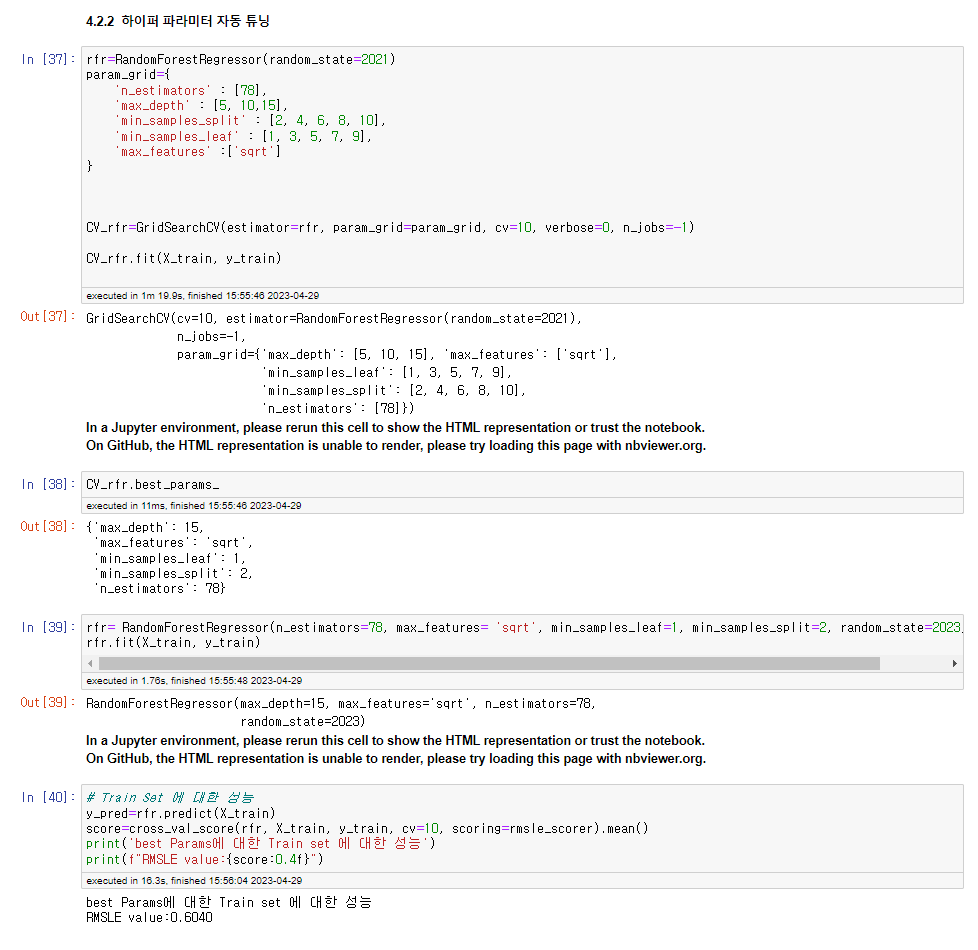
랜덤포레스트를 사용하는 코드는 생각보다 간단합니다. RandomForsetRegressor 실행 후 fit을 하고 Score를 앞서 정한 RMSLE로 스코어를 평가하면 될 것 같습니다. 회귀에는 정말 다양 한 하이퍼 파라미터가 있습니다, 그러니까 RandomForestRegressor 안에서 값을 변화시킬 수 있 는 변수가 많다는 뜻입니다 ! 우선은 다양한 하이퍼 파라미터 중 n_estimators만 변화를 주어 값 을 나타내보도록 하겠습니다. n_estimators는 생성할 결정트리의 개수입니다. 일반적으로 큰 트리 의 개수가 많을수록 성능은 좋지만 계산에 대한 성능이 오래걸립니다. 외에도 max_features, max_depth, min_samples_split, min_samples_leaf 정도가 고려할 주요 파라미터인데 순서대로 분할에 사용할 최대 피쳐의 개수로 분산이 큰 피쳐가 존재할 경우 그 값을 작게 하고자 하는 것이고 ‘sqrt’ 와 ‘log2’가 있습니다. 다음은 결정트리의 최대 깊이이며 너무 작으면 과소적합 이 발생할 수 있고 너무 크면 과적합이 발생할 가능성이 있어 일반적으로 5~30의 값을 사용합니 다. 다음은 노드를 분할하기 위한 최소한의 샘플 개수입니다. 불균형 데이터셋이나 노이즈가 많은 경우 크게 설정하도록 하고 1~10 정도가 권장값입니다. 다음은 리프노드가 되기위한 최소한의 샘 플개수이고 작게 설정하면 분산이 커질 수 있고 크게 설정하면 과소적합이 될 가능성이 있습니다. 일반적으로 1~10의 값을 권장합니다. 다양한 하이퍼 파라미터가 있고 다양한 조합이 발생할 수 있어 이 부분에 대해 최적의 조합을 찾 는 것이 중요하겠죠 파이썬에서는 GridSearchCV를 제공합니다. 방금 앞서 말씀드린 변수들의 조합을 직접 계산해 그 중 최적의 방법을 찾아 출력해주는 기능입니다. 조합을 찾은 하이퍼 파라미터에 대한 fit을 진행하고 predict를 하여 목적값인 y_test를 얻어냅니다. 그 후에 그래프로 비교를 해보면 될 것 같습니다.


https://www.kaggle.com/c/bike-sharing-demand/
Bike Sharing Demand | Kaggle
www.kaggle.com
해당 링크에서 제공하는 데이터로 진행해본 머신러닝 입문용 대회이니 관심이 있다면 try 해보셔도 흥미로울 것 같아 소개해드리고 진행했던 내용을 공유해보았습니다. !
'IE & SWCON > Data Science' 카테고리의 다른 글
| 새로운 비만 평가 지표를 만들기 위해서 (2) (1) | 2023.11.14 |
|---|---|
| 새로운 비만 평가 지표를 만들기 위해서 (1) (0) | 2023.11.10 |
| [금융공공데이터취합] 재정패널조사 (0) | 2023.09.16 |
| [부스트코스] 건강정보데이터 분석하기 (0) | 2023.03.22 |
| [부스트코스]서울시 의료기관(종합병원) 분포확인하기 (0) | 2023.03.16 |