* 혼자공부하는 머신러닝+딥러닝의 교재의 학습 요약 내용입니다
https://hongong.hanbit.co.kr/%ED%98%BC%EC%9E%90-%EA%B3%B5%EB%B6%80%ED%95%98%EB%8A%94-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EB%94%A5%EB%9F%AC%EB%8B%9D/
혼자 공부하는 머신러닝+딥러닝
혼자 공부하는 머신러닝 딥러닝, 무료 동영상 강의, 머신러닝+딥러닝 용어집을 다운로드 하세요. 포기하지 마세요! 독학으로 충분히 하실 수 있습니다. ‘때론 혼자, 때론 같이’ 하며 힘이 되겠
hongong.hanbit.co.kr
* 경희대학교 데이터분석 동아리 KHUDA의 2023년 8월 기초세션 5주차 학습내용입니다.
https://cafe.naver.com/khuda
KHUDA : 네이버 카페
경희대학교 데이터 분석 동아리 KHUDA
cafe.naver.com
* 2차배포 및 상업적의도로의 사용 목적 및 의도가 없습니다
* 모든 저작권은 책 출판사 한빛미디어에 있습니다 !
Q1. (준용) k-means clustering 에서 초기의 k 값을 정할 때 random 으로 정하다보니 비효율적이라고 느껴진다. 혹시 random이 아닌 방법으로 초기 값을 정할 수 있을까?
1. Rule of thumb
k 값에 대한 정보가 전혀 없을 때 사용하는 방법 중에 하나

를 사용하긴 한다.
2. k-means ++
k-평균 클러스터링은 초기 값을 어떻게 선택 하는가에 따라 성능이 크게 달라지는 성질을 가지고 있다. 2007년 David Arthur와 Sergei Vassilvitskii은 이러한 성질로 인한 피해를 줄이기 위해 k-평균++을 제안하였다. k-평균++ 알고리즘은 k-평균 클러스링 알고리즘의 초기 값을 선택하는 알고리즘이다.

k-평균++ 알고리즘은 초기 값을 설정하기 위해 추가적인 시간을 필요로 하지만, 이후 선택된 초기 값은 이후 k-평균 알고리즘이 O(log k)의 시간 동안 최적 k-평균 해를 찾는 것을 보장한다. 일반적으로 데이터 마이닝에서 사용된다.
random으로 k값을 정한다면 일부 경우에 따라 오래걸릴 수도 있지만 k means ++의 경우 더 빠르게 진행되기도 한다.
3. k -means clustering에서 올바른 k 값 선정이 필요한 이

4. 사용 방법
from sklearn.cluster import KMeans
model = KMeans(n_cluster = k, init = 'k-means++)
Q2. (호윤) k-means clustering에 대한 기본적인 내용







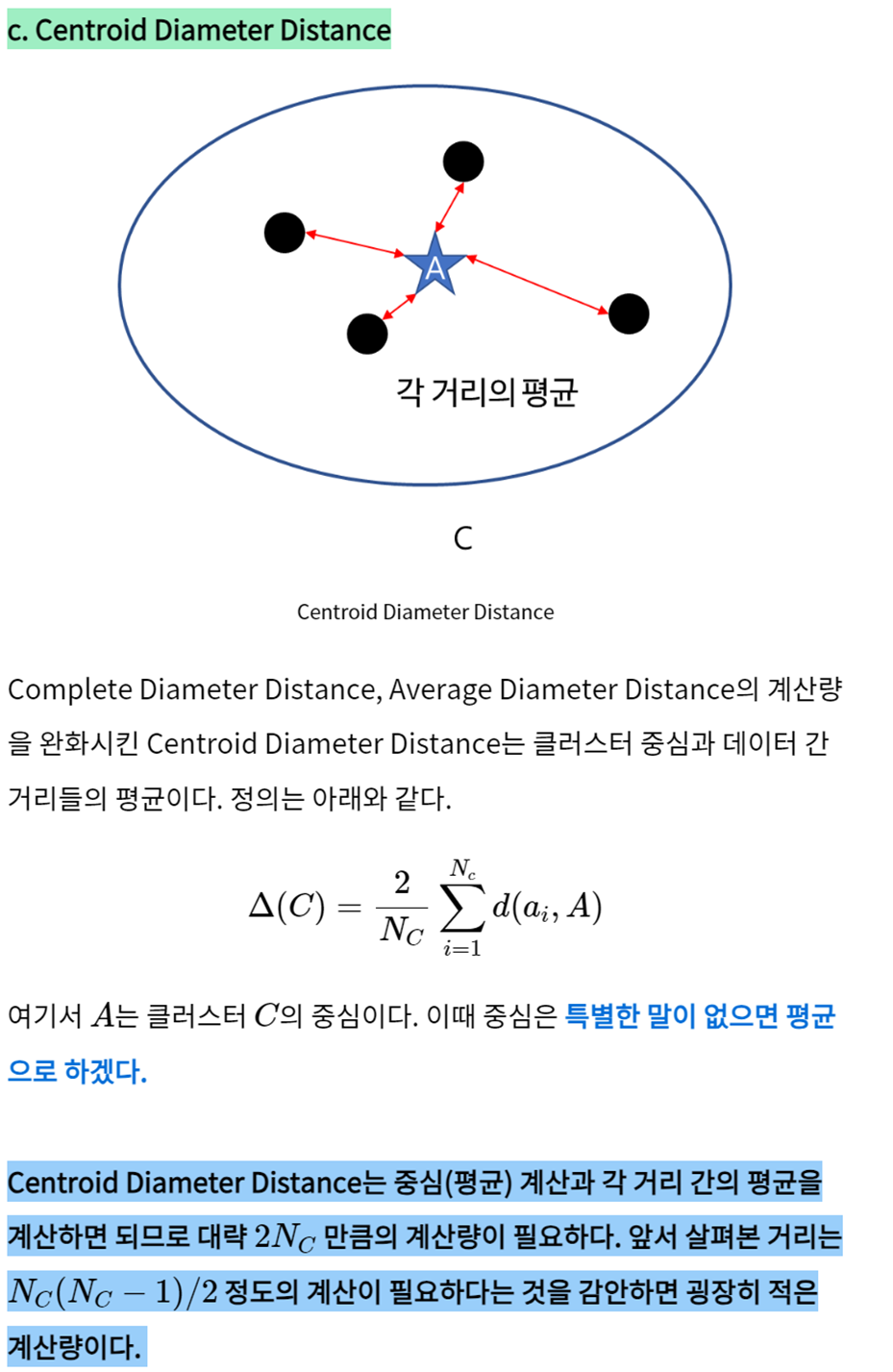


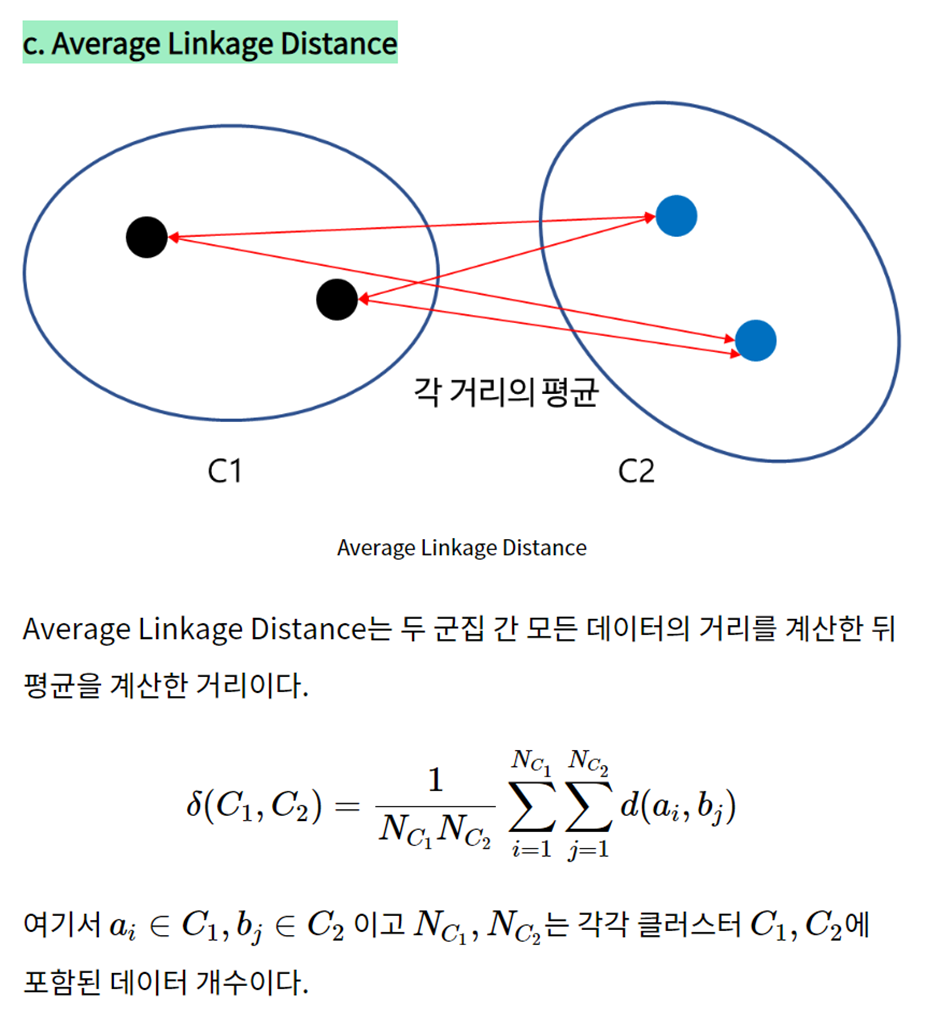

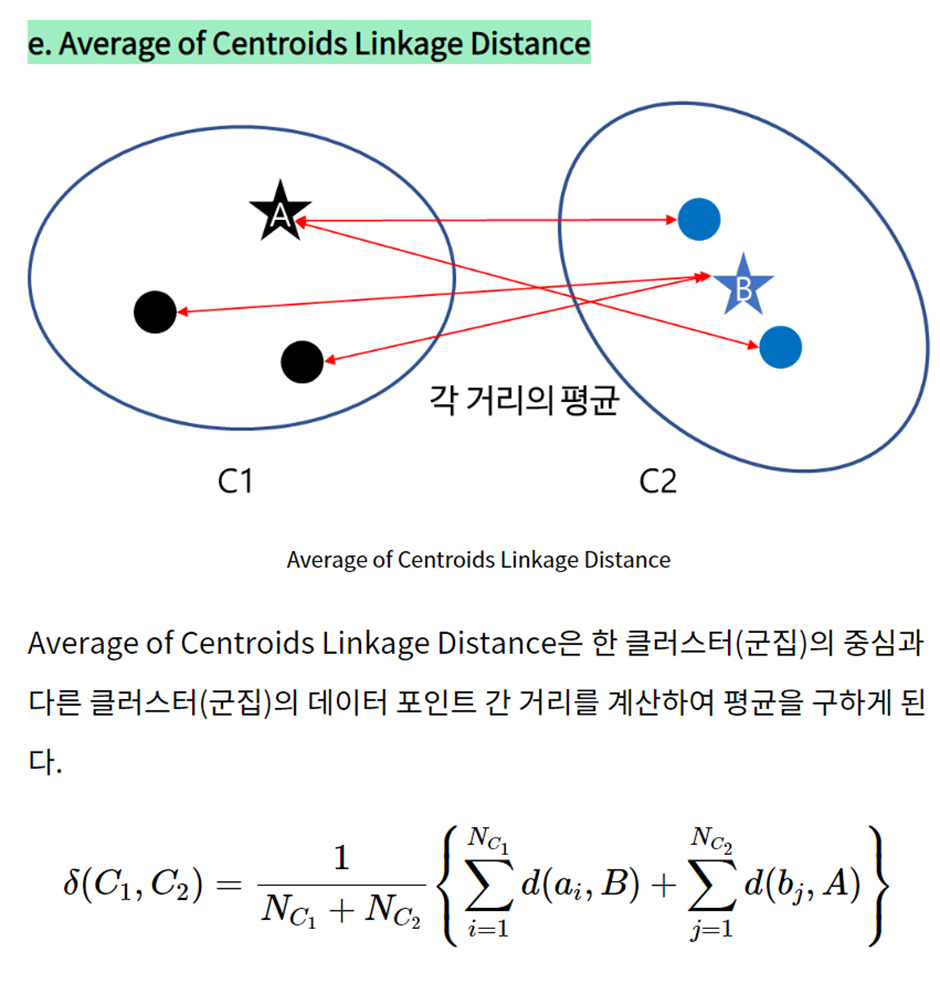
Q3. (수현) 실루엣 계수에 대하여


실루엣 계수: 각각의 데이터가 해당 데이터와 같은 군집 내의 데이터와는 얼마나 가깝게 군집화가 되었고, 다른 군집에 있는 데이터와는 얼마나 멀리 분포되어 있는지를 나타내는 지표
è 이가 가질 수 있는 값은 -1~1이며, 1에 가까울수록 군집화가 잘 되었음을 의미
데이터 하나에 대한 실루엣 계수만 좋다고 군집화가 잘 이루어졌다고 일반화는 불가
(각 군집별 데이터의 수가 고르게 분포되어야 + 각 군집별 실루엣 계수 평균값이 전체 실루엣 계수 평균값에 크게 벗어나지 않아야)
위 그림은 군집별로 실루엣 계수를 시각화한 예시이다. 빨간 점선은 전체 실루엣 계수의 평균을 의미한다. 어떠한 군집화가 잘 이루어졌는지 판단해보자.

군집 갯수 = 2, 평균 실루엣 계수 0.705
군집별 실루엣 계수 평균값이 0보다 크고 편차가 크지 않지만, 두 군집의 데이터 수의 차이가 많다.
군집 갯수 = 3, 평균 실루엣 계수 0.588
2번 군집에 실루엣 계수가 음수인 데이터들이 존재한다. 이는 2번 군집의 실루엣 계수와 전체 실루엣 계수에 편차가 큰 것을 의미한다.
군집 갯수 = 4, 평균 실루엣 계수 0.651
모든 군집의 데이터 수의 비율이 고른 편이고, 실루엣 계수가 음수인 데이터들도 존재하지 않으므로 최적의 군집화 결과로 판단된다.
응집도 (Inertia)
: 각 군집별 중심점으로부터 개별 데이터와의 거리의 제곱의 합


xi는 i번째 데이터 즉, 개별 데이터를 의미한다. μk는 k번째 클러스터의 중심이다. w(i,k)^
는 xi가 k번째 클러스터에 속하는 경우 1, 그렇지 않은 경우 0으로 정의
è 각 군집별 데이터들의 중심점과의 편차 제곱 합(각 군집별 분산)을 모든 군집별로 합한 값
군집의 갯수가 늘어날수록 각 군집별 데이터의 수가 줄어들기 때문에 일반적으로는 inertia는 감소한다. (0으로 수렴한다.) 하지만, 무조건 inertia가 작다고 좋은 것은 아님.
'IE & SWCON > Machine Learning' 카테고리의 다른 글
| 로지스틱 회귀를 사용한 클래스 확률 모델링 (1) | 2023.11.27 |
|---|---|
| Regression Line fitting - 선형 회귀/Normal Equation/Non-linear(polynomial)/릿지,라쏘 규제 (0) | 2023.11.26 |
| [혼공머딥] chapter 6 (0) | 2023.08.29 |
| [혼공머딥] chapter 5 (1) | 2023.08.22 |
| [혼공머딥] chapter 4 (0) | 2023.08.15 |