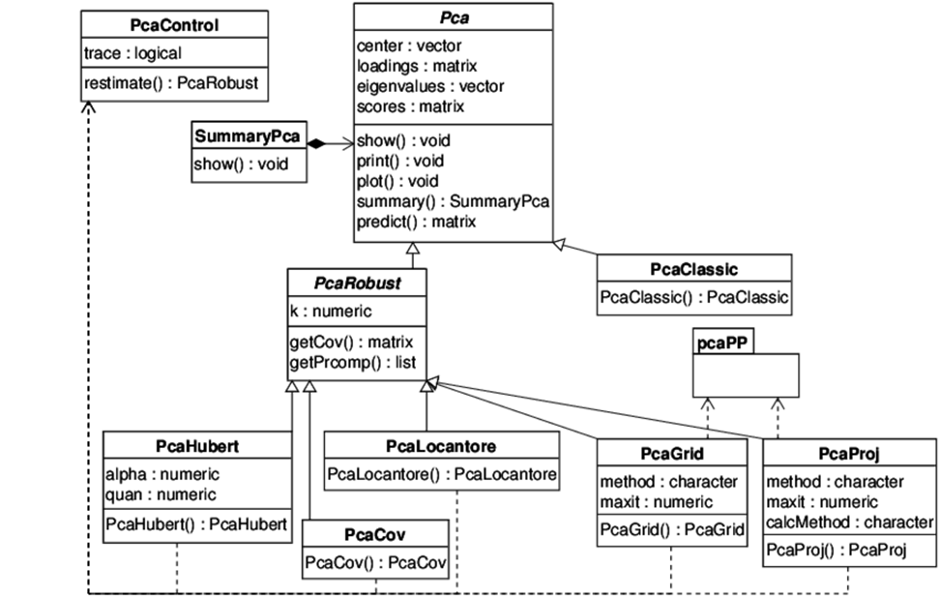
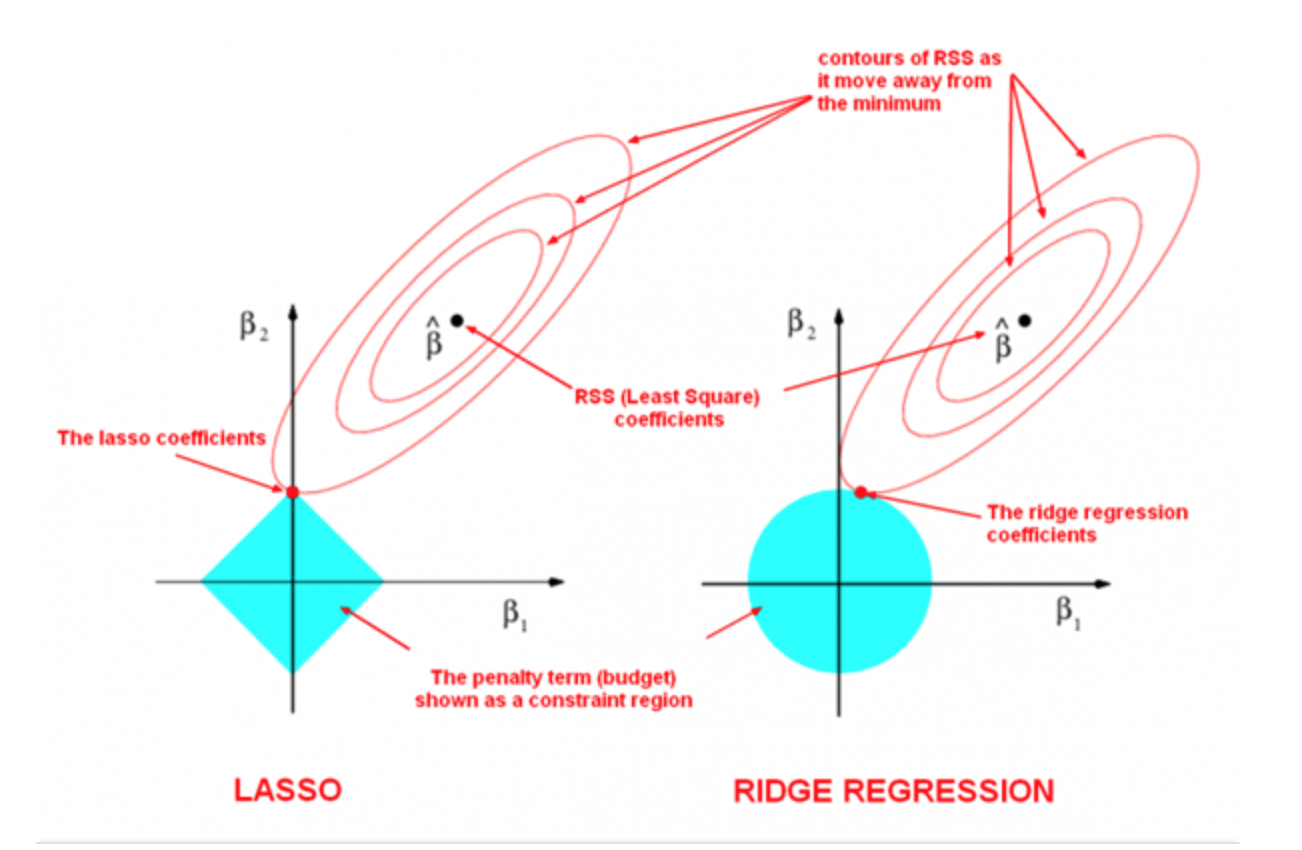
새로운 비만 평가 지표를 만들기 위해서 (1)
sim et al.(2006)에서는 단순비만지표로는 허리둘레(waist circumference, WC), 허리 엉덩이 둘레 (waist-hip ratio, WHR), 허리둘레 신장 비 (waist-stature ratio, WSR), 그리고 가장 대표적인 체질량지수(BMI)등이 있다. 그러나 연구자료에 따라 비만도 측정방법과 비만기 , 준의 차이가 있으므로 한국인의 비만 유병률이 상 이하게 보고되고 있으며, 특히 단순비만지표는 대부분 한국인 체형과는 다른 서구인을 근거로 하여 측정되었다 그러나 한국인은 신장과 엉덩이둘 . 레가 서양인보다 유의하게 작아 서구의 비만기준을 그대로 적용하기에 많은 문제점이 나타나고 있으며 , 동양인은 서양인보다 동일 체질량지수에서 내장지방이 더 많으며, 제지방량은 적어 비만..