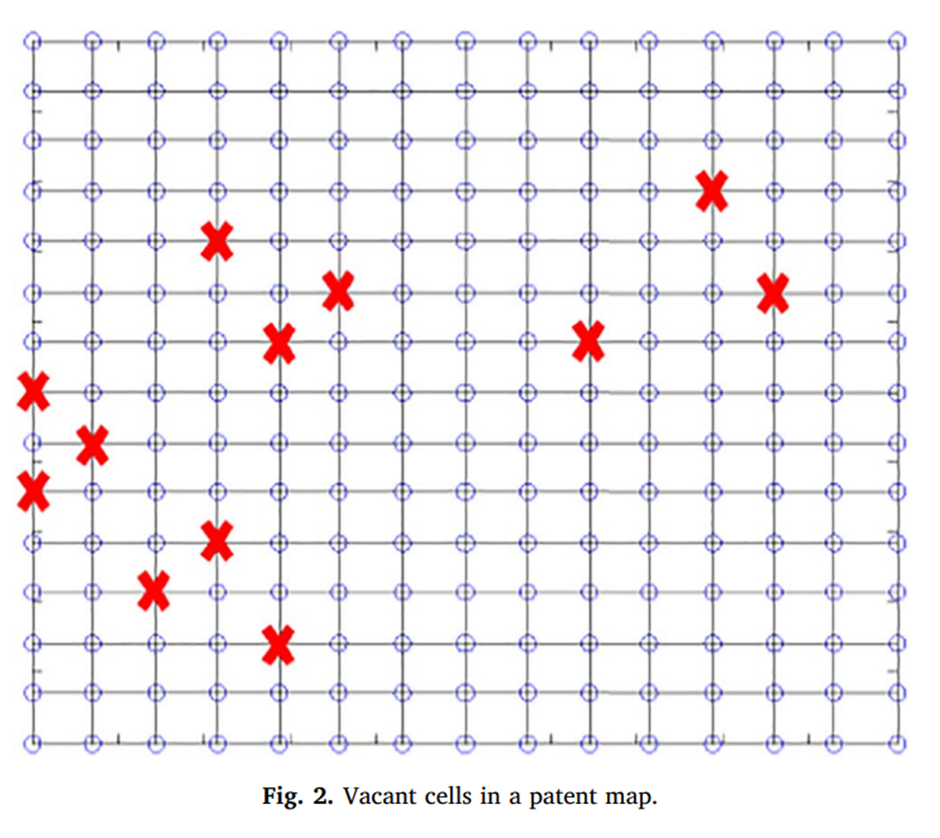
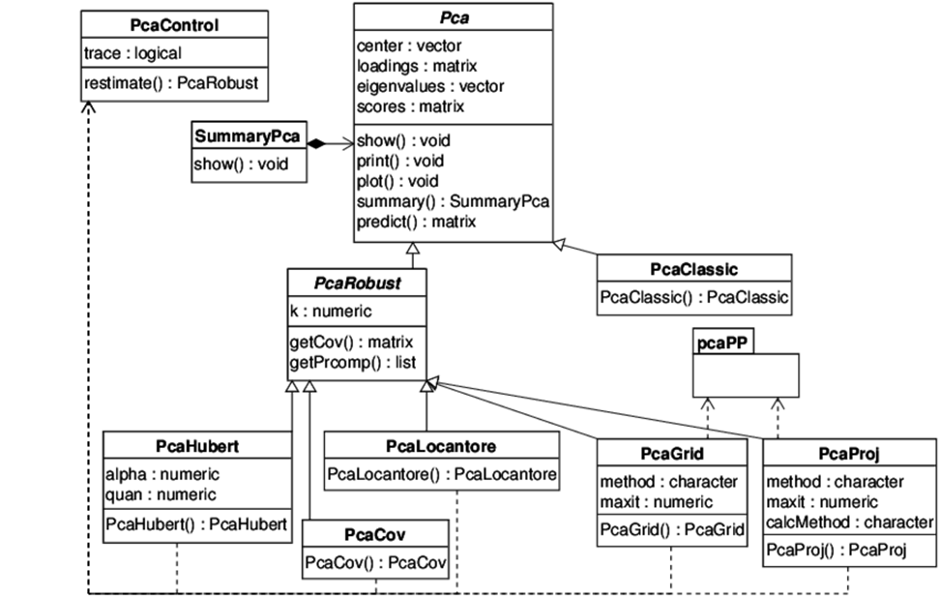
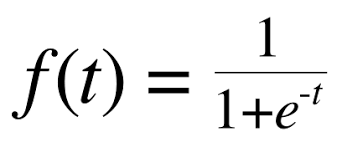전역하고 어떻게 보면 첫 해가 지난다. 국방의 의무라는 20대 남자의 큰 산을 등반한 동시에 코로나로부터 독립된 첫 대학생활이 기다리고 있었고 중간중간 아르바이트, 대외활동, 프로젝트가 있었다. 신기하고 감사한 2023년이었다. 기존의 인연보다 새로눈 인연을 많이 만날 수 있었고 때로는 극 내향적인 성으로 빠르게 친해지지 못한것도 같다. 그렇지만 1년동안 너무 좋은 경험을 했고 좋았다면 추억이었고 나빠도 기억으러는 남을 시간이었다. 굿바이와 웰컴의 1월에서 다시 새롭게 2024년의 목표를 세워보자면 토익 점수 확보 학점 관리 (학부 우수졸업 장학용)연구활동 열심히ADP 필기시험 합격 이정도가 학업적으로 이뤄야 할 목표라고 보여진다. 원래는 1월 1일에 기록하려 했으나 미루고 미루다가 이제야 적는다. 아,..